How to use OpenRouter API Key for AI chat

About OpenRouter
Latest models available:
- GPT-5: OpenAI's flagship model
- Claude 3.5 Sonnet: Anthropic's best model
- Gemini 2.5 Flash: Google's advanced model
- Llama 3.1 405B: Meta's open-source model
Key features:
- Single API for multiple providers
- Competitive pricing
- Latest model access
- Transparent usage tracking
Step by step guide to use OpenRouter API Key to chat with AI
1. Get Your OpenRouter API Key
First, you'll need to obtain an API key from OpenRouter. This key allows you to access their AI models directly and pay only for what you use.
- Visit OpenRouter's API console
- Sign up or log in to your account
- Navigate to the API keys section
- Generate a new API key (copy it immediately as some providers only show it once)
- Save your API key in a secure password manager or encrypted note
2. Connect Your OpenRouter API Key on TypingMind
Once you have your OpenRouter API key, connecting it to TypingMind to chat with AI is straightforward:
Method 1: Direct Import (Recommended)
- Open TypingMind in your browser
- Click the "Settings" icon (gear symbol)
- Navigate to "Manage Models" section
- Click "Add Custom Model"
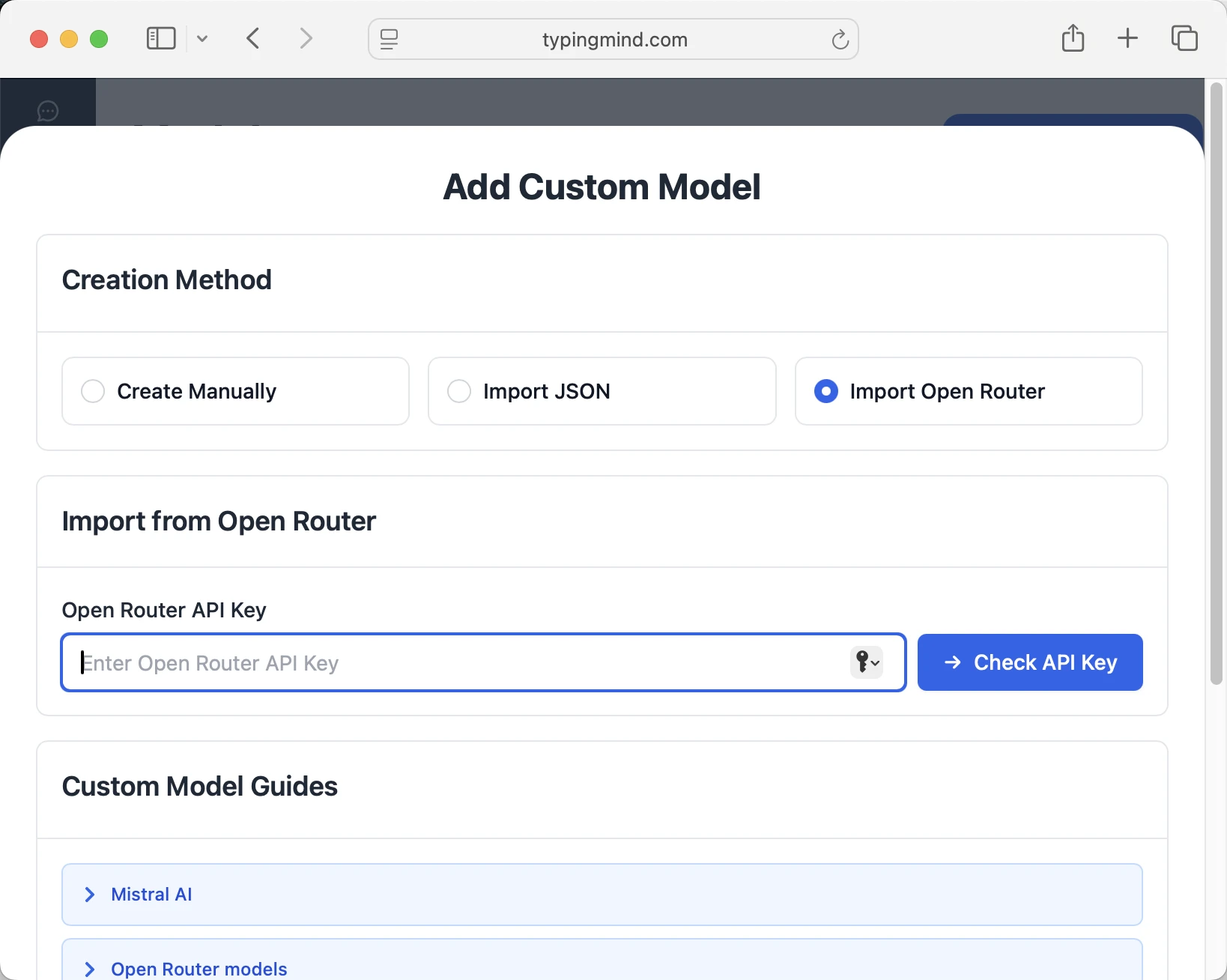
- Select "Import OpenRouter" from the options
- Enter your OpenRouter API key from Step 1
- Click "Check API Key" to verify the connection
- Choose which models you want to add from the list (you can add multiple at once)
- Click "Import Models" to complete the setup
Method 2: Manual Custom Model Setup
- Open TypingMind in your browser
- Click the "Settings" icon (gear symbol)
- Navigate to "Models" section
- Click "Add Custom Model"
- Fill in the model information:Name:
openai/gpt-5 via OpenRouter(or your preferred name)Endpoint:https://openrouter.ai/api/v1/chat/completionsModel ID:openai/gpt-5for example (check OpenRouter model list)Context Length: Enter the model's context window (e.g., 32000 for openai/gpt-5)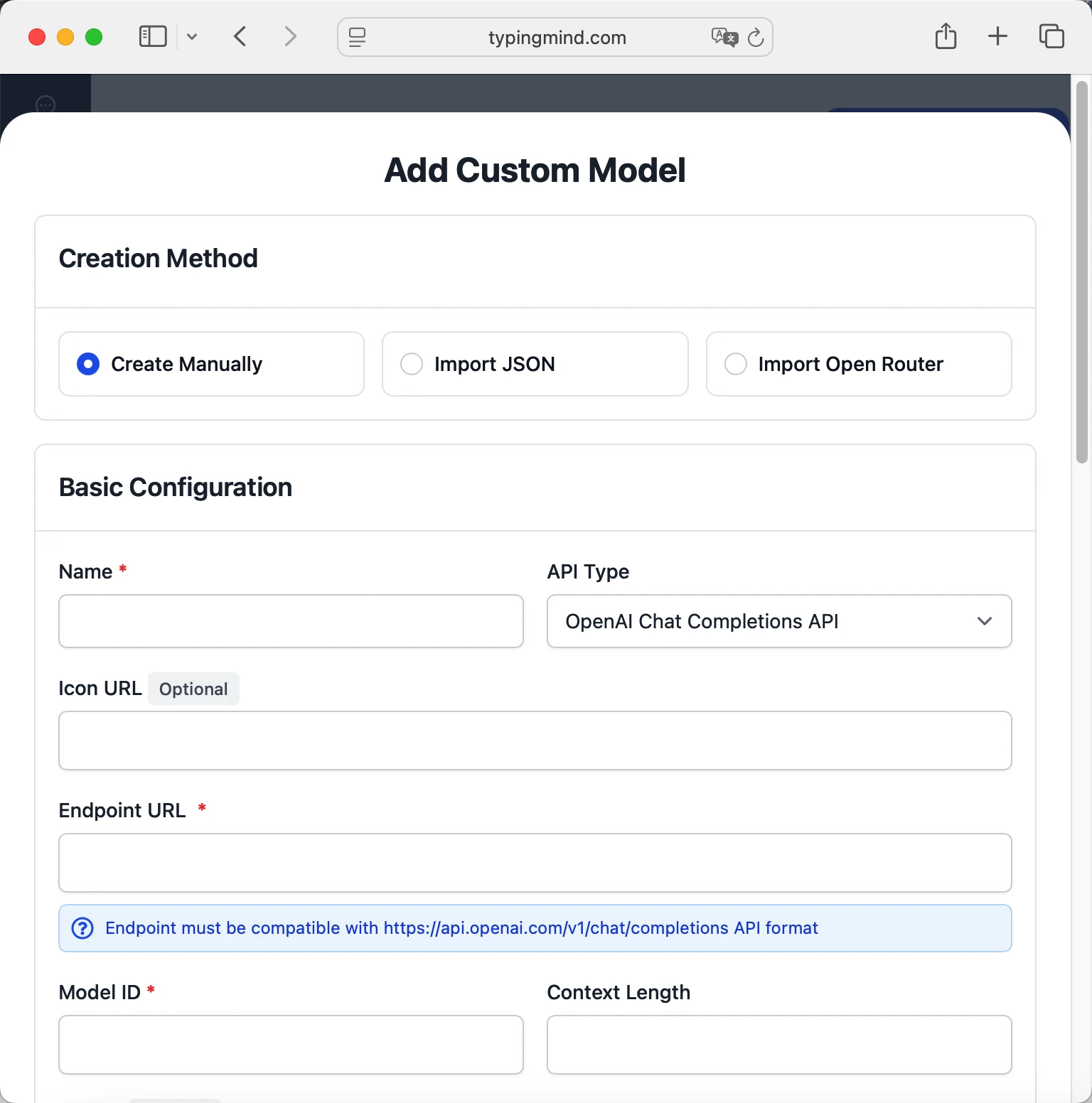 openai/gpt-5https://openrouter.ai/api/v1/chat/completionsopenai/gpt-5 via OpenRouterhttps://www.typingmind.com/model-logo.webp32000
openai/gpt-5https://openrouter.ai/api/v1/chat/completionsopenai/gpt-5 via OpenRouterhttps://www.typingmind.com/model-logo.webp32000 - Add custom headers by clicking "Add Custom Headers" in the Advanced Settings section:Authorization:
Bearer <OPENROUTER_API_KEY>:X-Title:typingmind.comHTTP-Referer:https://www.typingmind.com - Enable "Support Plugins (via OpenAI Functions)" if the model supports the "functions" or "tool_calls" parameter, or enable "Support OpenAI Vision" if the model supports vision.
- Click "Test" to verify the configuration
- If you see "Nice, the endpoint is working!", click "Add Model"
3. Start Chatting with OpenRouter models
Now you can start chatting with OpenRouter models through TypingMind:
- Select your preferred OpenRouter model from the model dropdown menu
- Start typing your message in the chat input
- Enjoy faster responses and better features than the official interface
- Switch between different AI models as needed
- Use specific, detailed prompts for better responses (How to use Prompt Library)
- Create AI agents with custom instructions for repeated tasks (How to create AI Agents)
- Use plugins to extend OpenRouter capabilities (How to use plugins)
- Upload documents and images directly to chat for AI analysis and discussion (Chat with documents)
4. Monitor Your AI Usage and Costs
One of the biggest advantages of using API keys with TypingMind is cost transparency and control. Unlike fixed subscriptions, you pay only for what you actually use. Visit https://openrouter.ai/settings/credits to monitor your OpenRouter API usage and set spending limits.
- Use less expensive models for simple tasks
- Keep prompts concise but specific to reduce token usage
- Use TypingMind's prompt caching to reduce repeat costs (How to enable prompt caching)
- Using RAG (retrieval-augmented generation) for large documents to reduce repeat costs (How to use RAG)

Access OpenAI: GPT-4.1 Mini via OpenRouter
GPT-4.1 Mini is a mid-sized model delivering performance competitive with GPT-4o at substantially lower latency and cost. It retains a 1 million token context window and scores 45.1% on hard instruction evals, 35.8% on MultiChallenge, and 84.1% on IFEval. Mini also shows strong coding ability (e.g., 31.6% on Aider’s polyglot diff benchmark) and vision understanding, making it suitable for interactive applications with tight performance constraints.

Access OpenAI: GPT-4.1 Nano via OpenRouter
For tasks that demand low latency, GPT‑4.1 nano is the fastest and cheapest model in the GPT-4.1 series. It delivers exceptional performance at a small size with its 1 million token context window, and scores 80.1% on MMLU, 50.3% on GPQA, and 9.8% on Aider polyglot coding – even higher than GPT‑4o mini. It’s ideal for tasks like classification or autocompletion.

Access EleutherAI: Llemma 7b via OpenRouter
Llemma 7B is a language model for mathematics. It was initialized with Code Llama 7B weights, and trained on the Proof-Pile-2 for 200B tokens. Llemma models are particularly strong at chain-of-thought mathematical reasoning and using computational tools for mathematics, such as Python and formal theorem provers.

Access AlfredPros: CodeLLaMa 7B Instruct Solidity via OpenRouter
A finetuned 7 billion parameters Code LLaMA - Instruct model to generate Solidity smart contract using 4-bit QLoRA finetuning provided by PEFT library.

Access ArliAI: QwQ 32B RpR v1 (free) via OpenRouter
QwQ-32B-ArliAI-RpR-v1 is a 32B parameter model fine-tuned from Qwen/QwQ-32B using a curated creative writing and roleplay dataset originally developed for the RPMax series. It is designed to maintain coherence and reasoning across long multi-turn conversations by introducing explicit reasoning steps per dialogue turn, generated and refined using the base model itself. The model was trained using RS-QLORA+ on 8K sequence lengths and supports up to 128K context windows (with practical performance around 32K). It is optimized for creative roleplay and dialogue generation, with an emphasis on minimizing cross-context repetition while preserving stylistic diversity.

Access ArliAI: QwQ 32B RpR v1 via OpenRouter
QwQ-32B-ArliAI-RpR-v1 is a 32B parameter model fine-tuned from Qwen/QwQ-32B using a curated creative writing and roleplay dataset originally developed for the RPMax series. It is designed to maintain coherence and reasoning across long multi-turn conversations by introducing explicit reasoning steps per dialogue turn, generated and refined using the base model itself. The model was trained using RS-QLORA+ on 8K sequence lengths and supports up to 128K context windows (with practical performance around 32K). It is optimized for creative roleplay and dialogue generation, with an emphasis on minimizing cross-context repetition while preserving stylistic diversity.

Access Agentica: Deepcoder 14B Preview (free) via OpenRouter
DeepCoder-14B-Preview is a 14B parameter code generation model fine-tuned from DeepSeek-R1-Distill-Qwen-14B using reinforcement learning with GRPO+ and iterative context lengthening. It is optimized for long-context program synthesis and achieves strong performance across coding benchmarks, including 60.6% on LiveCodeBench v5, competitive with models like o3-Mini

Access Agentica: Deepcoder 14B Preview via OpenRouter
DeepCoder-14B-Preview is a 14B parameter code generation model fine-tuned from DeepSeek-R1-Distill-Qwen-14B using reinforcement learning with GRPO+ and iterative context lengthening. It is optimized for long-context program synthesis and achieves strong performance across coding benchmarks, including 60.6% on LiveCodeBench v5, competitive with models like o3-Mini

Access MoonshotAI: Kimi VL A3B Thinking (free) via OpenRouter
Kimi-VL is a lightweight Mixture-of-Experts vision-language model that activates only 2.8B parameters per step while delivering strong performance on multimodal reasoning and long-context tasks. The Kimi-VL-A3B-Thinking variant, fine-tuned with chain-of-thought and reinforcement learning, excels in math and visual reasoning benchmarks like MathVision, MMMU, and MathVista, rivaling much larger models such as Qwen2.5-VL-7B and Gemma-3-12B. It supports 128K context and high-resolution input via its MoonViT encoder.

Access MoonshotAI: Kimi VL A3B Thinking via OpenRouter
Kimi-VL is a lightweight Mixture-of-Experts vision-language model that activates only 2.8B parameters per step while delivering strong performance on multimodal reasoning and long-context tasks. The Kimi-VL-A3B-Thinking variant, fine-tuned with chain-of-thought and reinforcement learning, excels in math and visual reasoning benchmarks like MathVision, MMMU, and MathVista, rivaling much larger models such as Qwen2.5-VL-7B and Gemma-3-12B. It supports 128K context and high-resolution input via its MoonViT encoder.

Access xAI: Grok 3 Mini Beta via OpenRouter
Grok 3 Mini is a lightweight, smaller thinking model. Unlike traditional models that generate answers immediately, Grok 3 Mini thinks before responding. It’s ideal for reasoning-heavy tasks that don’t demand extensive domain knowledge, and shines in math-specific and quantitative use cases, such as solving challenging puzzles or math problems. Transparent "thinking" traces accessible. Defaults to low reasoning, can boost with setting `reasoning: { effort: "high" }` Note: That there are two xAI endpoints for this model. By default when using this model we will always route you to the base endpoint. If you want the fast endpoint you can add `provider: { sort: throughput}`, to sort by throughput instead.

Access xAI: Grok 3 Beta via OpenRouter
Grok 3 is the latest model from xAI. It's their flagship model that excels at enterprise use cases like data extraction, coding, and text summarization. Possesses deep domain knowledge in finance, healthcare, law, and science. Excels in structured tasks and benchmarks like GPQA, LCB, and MMLU-Pro where it outperforms Grok 3 Mini even on high thinking. Note: That there are two xAI endpoints for this model. By default when using this model we will always route you to the base endpoint. If you want the fast endpoint you can add `provider: { sort: throughput}`, to sort by throughput instead.